Chúng tôi tin rằng Trí tuệ Nhân tạo sẽ trở thành tiến bộ công nghệ quan trọng nhất và có nhiều lợi ích nhất từ trước đến giờ, giúp loài người giải quyết được những vấn đề lớn mà chúng ta phải đối mặt, từ biến đổi khí hậu tới hệ thống y tế tân tiến. Nhưng để AI có thể thực hiện điều đó, chúng tôi biết rằng công nghệ này phải được xây dựng với một thái độ có trách nhiệm và chúng tôi phải tính đến tất cả những thử thách và nguy cơ tiềm tàng.
Chính vì thế mà những nhà sáng lập của DeepMind khởi xướng Partnership on AI to Benefit People and Society và vì vậy mà chúng tôi có một nhóm chuyên đảm bảo An toàn kỹ thuật AI. Nghiên cứu trong lĩnh vực này cần phải có tính mở và hợp tác để đảm bảo rằng những thực nghiệm tốt nhất được thực hiện một cách rộng rãi nhất có thể, vì vậy mà chúng tôi cũng hợp tác với OpenAI trong nghiên cứu về An toàn Kỹ thuật AI.
Một trong những câu hỏi cốt lõi của lĩnh vực này là làm sao để con người có thể yêu cầu một hệ thống làm điều chúng ta muốn và quan trọng là những gì chúng ta không muốn nó làm. Việc này càng ngày càng quan trọng hơn khi mà những vấn đề chúng ta gặp phải với machine learning đang ngày càng phức tạp và được áp dụng trong thực tiễn.
Kết quả đầu tiên từ sự hợp tác của chúng tôi mô tả một phương pháp để giải quyết vấn đề nêu trên, bằng cách cho những người không có kinh nghiệm về kỹ thuật để dạy cho một hệ thống Reinforcement learning (RL) – một AI học bằng cách thử sai – một mục tiêu rất phức tạp. Như vậy con người sẽ không cần đưa ra một mục tiêu cụ thể ban đầu cho hệ thống. Đây là một bước quan trọng bởi vì hiểu sai mục tiêu một chút thôi cũng có thể dẫn tới những hành vi không mong muốn hay thậm chí nguy hiểm. Trong một số trường hợp, chỉ 30 phút phản hồi từ một người bình thường cũng đủ để huấn luyện hệ thống, bao gồm cả dạy cho nó một hành vi phức tạp hoàn toàn mới, như dạy một robot giả lập cách nhảy blackflips.

Hệ thống – được miêu tả trong nghiên cứu của chúng tôi Deep Reinforcement Learning from Human Preferences – khác với một hệ thống RL thông thường ở chỗ nó huấn luyện agent (robot hoặc AI) bằng một neural network theo kiểu dự đoán phần thưởng “reward predictor” hơn là kiểu thu thập phần thưởng trong khi agent khám phá một môi trường.
Nó bao gồm ba tiến trình chạy song song:
1.Một Agent Reinforcement learning khám phá và tương tác với môi trường quanh nó, ví dụ như các trò chơi trên máy Atari.
2.Định kỳ, một cặp video clip dài 1 tới 2 giây quay các hoạt động của agent tới một điều hành viên con người và hỏi xem hoạt động trong video nào là cách tốt nhất để đạt được mục tiêu mong muốn.
3.Lựa chọn của con người được dùng để huấn luyện một “reward predictor” , rồi sau đó predictor này sẽ huấn luyện agent. Qua thời gian, agent sẽ học cách để tối đa hóa phần thưởng và cải thiện hành vi của nó theo lựa chọn của con người.
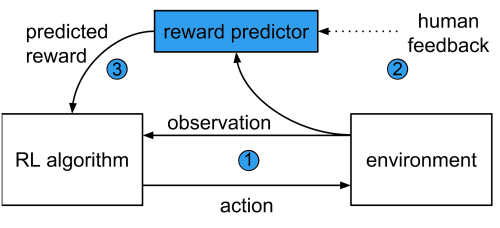
Phương pháp học tập lặp lại này đồng nghĩa với việc con người có thể phát hiện và chỉnh sửa bất kỳ hành vi không mong muốn nào, một điểm rất quan trọng của bất kỳ hệ thống an toàn nào. Cơ chế này cũng sẽ không dồn một khối lượng công việc quá lớn lên điều hành viên con người, họ chỉ phải duyệt qua khoảng 0.1% số lượng hành vi của agent để có thể khiến agent thực hiện những gì họ muốn. Tuy vậy, điều hành viên cũng phải duyệt qua vài trăm tới vài nghìn cặp video clip nên thuật toán cần được cải thiện để có thể áp dụng vào các vấn đề thực tiễn.

Trong trò Enduro, người chơi phải lái một chiếc xe để vượt qua những xe khác. Với trò này thì rất khó để agent có thể học chơi trò này bằng phương pháp thử sai trong thuật toán RL trước đây, phản hồi của con người cuối cùng cũng cho phép hệ thống của chúng tôi đạt được kết quả như con người. Trong những trò chơi khác và các tác vụ robot giả lập, hệ thống của chúng tôi đạt được những kết quả có thể so sánh với hệ thống RL thông thường trong khi một số trò khác như Qbert và Breakout thì nó không thể thực hiện tác vụ.
Nhưng mục tiêu cuối cùng của một hệ thống như này là cho phép con người đặt một mục tiêu cụ thể cho agent kể cả khi nó không xuất hiện trong môi trường. Để kiểm tra việc này, chúng tôi dạy agent nhiều hành vi mới lạ như nhảy backflip, bước đi trên một chân hay học lái xe song song với một xe khác trong Enduro hơn là vượt qua để lấy điểm số cao.

Mục tiêu thông thường của trò Enduro là vượt qua nhiều xe nhất có thể. Tuy nhiên trong hệ thống của chúng tôi, chúng tôi có thể dạy cho agent một mục tiêu hoàn toàn khác, như là lái song song một chiếc xe khác.
Mặc dù những bài kiểm tra đó cho thấy một vài kết quả khả quan, một số khác cho thấy những hạn chế của hệ thống. Cụ thể hơn, cài đặt của chúng tôi dễ bị reward hacking hay đánh lừa hàm tính thưởng – nếu phản hồi của con người bị ngắt quãng trong giai đoạn đầu của huấn luyện. Trong trường hợp đó, agent sẽ tiếp tục khám phá môi trường game trong khi reward predictor bị buộc phải ước lượng phần thưởng cho các tình huống mà nó không nhận được phản hồi nào. Việc này có thể dẫn tới đánh giá quá cao phần thưởng, khiến agent học những hành vi sai, thường là kỳ lạ. Một ví dụ có thể thấy ở video tiếp theo, khi mà agent nhận thấy đập bóng qua lại là một chiến thuận tốt hơn là thắng hay mất điểm.

Agent đã qua mặt hàm tính thưởng của chính nó, và quyết định chỉ đánh bóng qua lại thay vì cố gắng ghi điểm hay để mất điểm.
Hiểu được những thiếu sót như vậy là tối quan trọng để đảm bảo chúng tôi tránh được những thất bại và phát triển được một hệ thống AI có hành vi như mong muốn.
Còn rất nhiều công việc phải làm để kiểm tra và nâng cấp hệ thống này, nhưng nó đã cho thấy một số bước đột phá đầu tiên trong việc xây dựng một hệ thống có thể được dạy bởi những người dùng không chuyên nghiệp, mang tính kinh tế với số lượng phản hồi mà nó cần và có thể mở rộng ra nhiều vấn đề khác.
Các lĩnh vực cần khám phá khác có thể bao gồm việc giảm thiểu số lượng phản hồi của con người hay cho phép con người phản hồi qua giao diện ngôn ngữ tự nhiên. Việc đó sẽ đánh dấu một bước thay đổi trong việc tao ra một hệ thống có thể dễ dàng học từ những hành vi phức tạp của con người và là một bước quan trọng hướng tới việc tạo ra AI có thể làm việc với và vì loài người.
Lưu ý: Bài viết này được các nhà khoa học của DeepMind viết dựa trên nghiên cứu chung với OpenAI. Các nhà khoa học của OpenAI cũng đã viết một bài blog khác dưới góc nhìn của họ. Chúng tôi sẽ giới thiệu tới độc giả bài viết đó trong tương lai gần.
Theo Shane Legg, Jan Leike, Miljan Martic (DeepMind)
Bài viết được dẫn nguồn tại đây: Tạp chí AI