Mặc dù Trí tuệ Nhân tạo mới được chú ý trong vài năm trở lại đây, nhưng những lý thuyết và kỹ thuật trong lĩnh vực này đã được liên tục nghiên cứu và phát triển trong hơn nửa thế kỷ qua. Cho đến năm 2017, khối lượng tri thức trong lĩnh vực này đã rất lớn và tăng ngày càng nhanh. Đó là nhờ sự đầu tư tích cực từ các tập đoàn công nghệ cũng như các trường đại học trên thế giới.
Tạp chí Trí tuệ nhân tạo số 1
Các nội dung chính trong số đầu tiên này
Mong muốn đem những kiến thức, thông tin về Trí tuệ Nhân tạo và Machine Learning đến gần với bạn đọc Việt Nam hơn, giúp công nghệ này dễ tiếp cận hơn với người Việt. Tạp trí Trí tuệ Nhân tạo Số đầu tiên sẽ giới thiệu tới các bạn đọc cái nhìn tổng quan nhất về Trí tuệ Nhân tạo. Sau đó là những kiến thức về Reinforcement Learning. Đó một phương pháp Machine Learning đang đạt được nhiều thành tựu trong phát triển Trí tuệ Nhân tạo hiện nay.
Tạp chí cũng sẽ cung cấp nhưng bài viết về những kiến thức cơ bản về toán học và lập trình cần thiết. Để bạn đọc, kể cả những người hoàn toàn chưa có kiến thức về lĩnh vực này, có thể bắt tay vào tìm hiểu và nghiên cứu AI.
Là số đầu tiên, Tạp chí khó tránh khỏi những sai sót không đáng có. Ban Biên Tập rất mong nhận được sự góp ý của độc giả để có thể nâng cao chất lượng nội dung của tạp chí. BBT cũng rất mong nhận được sự đóng góp về ý tưởng và bài viết của các bạn độc giả. Mọi chi tiết xin liên hệ [email protected]
Trí tuệ nhân tạo (AI) đang giúp định hình thế giới theo cách tốt đẹp hơn, nhưng cũng có những lo ngại một ngày nào đó máy móc sẽ kiểm soát con người.
Máy móc liệu có kiểm soát con người?
Những tên tuổi lớn đang đầu tư mạnh tay cho trí tuệ nhân tạo hiện nay gồm có Google, Facebook, Amazon, IBM, Microsoft và một số hãng khác. Những hãng này đã lập ra một đối tác trí tuệ nhân tạo mới với trọng tâm nghiên cứu và định hình những hoạt động tốt nhất cho công nghệ AI.
Dự án đối tác này sẽ tạo ra một diễn đàn mở về AI, nơi những người quan tâm có thể trao đổi, thảo luận, đồng thời tăng cường sự hiểu biết của cộng đồng về trí tuệ nhân tạo.
Ngạc nhiên ở chỗ, Elon Musk – sáng lập SpaceX và đồng sáng lập Tesla Motors – cùng với PayPal không tham gia đối tác này. Apple cũng vậy.
Google
Năm 2014, Google mua lại công ty khởi nghiệp trí tuệ nhân tạo DeepMind với giá 400 triệu USD – vốn được xem là một trong những thương vụ mua bán lớn nhất trong lĩnh vực AI.
Google DeepMind vừa xây dựng một dự án AI cho hệ thống tàu điện ngầm London, sử dụng mạng thần kinh để lưu trữ dữ liệu và truy vấn các thông tin nhằm giải quyết các sự cố phát sinh.
Google là hãng tiên phong trong lĩnh vực trí tuệ nhân tạo.
Nhiệm vụ của dự án là giúp tìm ra những tuyến đường di chuyển nhanh nhất giữa các trạm dừng để hành khách có thể đi lại nhanh hơn và thuận tiện hơn.
Đầu năm vừa rồi, Google cũng ra mắt hệ thống học máy TensorFlow miễn phí cho tất cả mọi người. Cơ chế học máy này có thể tìm thấy trong công nghệ nhận dạng thoại & hình ảnh và các ứng dụng dịch thuật.
TensorFlow có thể bắt chước cơ chế hoạt động của não người, nhận dạng và ghi nhớ các mẫu xác định.
Facebook
Mạng xã hội này đang dùng công nghệ trí tuệ nhân tạo để giúp người khiếm thị có thể “nhìn thấy” ảnh qua một ứng dụng trên iOS.
Ngoài ra, công nghệ này còn được Facebook dùng để tạo các bản đồ chi tiết về dân số và người truy cập Internet toàn cầu. Mục đích là giúp hãng này triển khai dự án phổ cập Internet tới các vùng xa xôi, hẻo lánh.
Mark Zuckerberg dùng trí tuệ nhân tạo để phân tích người dùng.
Facebook cũng có công nghệ AI học sâu dùng để nghiên cứu hành vi người dùng. Năm 2010, hãng từng giới thiệu công nghệ nhận dạng khuôn mặt giúp xác định danh tính của người trong ảnh đăng trên mạng xã hội.
Năm 2013, “ông trùm” Mark Zuckerberg còn lập riêng một phòng thí nghiệm chuyên về trí tuệ nhân tạo. Nói chung, Facebook là gương mặt khá quen thuộc trong lĩnh vực AI.
Apple
Đầu năm vừa rồi, hãng Quả táo đã mua công ty khởi nghiệp về trí tuệ nhân tạo Emotient nhưng chưa rõ kế hoạch triển khai các dự án liên quan sẽ như thế nào. Có vẻ như Apple sẽ tập trung vào công nghệ nhận diện khuôn mặt và phản ứng của khách hàng với quảng cáo.
Apple cũng là một tay chơi lớn trong lĩnh vực AI.
Apple cũng là một tay chơi lớn trong lĩnh vực AI.
Trước đó vào tháng 10/2015, Apple mua công ty trí tuệ nhân tạo Vocal IQ nhằm phát triển Siri lên mức cao hơn, đồng thời sử dụng phần mềm trí tuệ nhân tạo giọng nói của Vocal IQ.
Vocal IQ chính là tác giả của công nghệ kiểm soát giọng nói trên các mẫu xe của General Motors, cho phép người lái có thể bật hoặc tắt những chức năng nhất định trên xe hơi bằng lệnh thoại.
Elon Musk
Elon Musk đang hợp sức với nhiều hãng công nghệ khổng lồ như Amazon, LinkedIn và PayPal phát triển trí tuệ nhân tạo nguồn mở. Dự án phi lợi nhuận này giúp phát triển các trí tuệ nhân tạo phục vụ cho lợi ích của con người.
Đã có những tiếng nói lo ngại về nguy cơ máy móc trỗi dậy.
Cùng với “ông hoàng vật lý” Stephen Hawking, Elon Musk là người lo lắng về nguy cơ của những dạng thức trí tuệ nhân tạo không được kiểm soát.
Microsoft
Hãng này có dự án Oxford giúp phân tích hành vi người dùng thông qua các giao diện chương trình ứng dụng (API) giọng nói, biểu cảm và khuôn mặt.
Dự án phân tích tâm trạng người trong ảnh của Microsoft.
Microsoft cũng mới công bố chương trình Future Decoded cho phép các nhà phát triển có thể tiếp cận dịch vụ phát hiện biểu cảm nhằm gán tâm trạng cho một người dựa trên biểu cảm khuôn mặt của họ.
Công nghệ nhận dạng khuôn mặt này cho phép các bức ảnh có thể được chỉnh sửa dựa trên tâm trạng của người trong ảnh.
IBM
Từng nổi tiếng với máy tính Watson (hệ thống máy tính có khả năng trả lời câu hỏi theo ngôn ngữ tự nhiên), IBM sử dụng trí tuệ nhân tạo để phân tích bối cảnh và ý nghĩa ẩn sau các bức ảnh, video, tin nhắn và lời thoại.
Năm 2011, Watson thắng giải Jeopardy, một chương trình đố vui kiến thức truyền hình tại Mỹ, xuất sắc vượt qua các đối thủ con người khác.
IBM có lịch sử phát triển trí tuệ nhân tạo lâu đời.
IBM còn hợp tác với nhà sản xuất chip đồ họa Nvidia để nâng cấp Watson mạnh gấp 1,7 lần so với trước đây.
Hiện IBM đang phát triển một ứng dụng trợ lý giảng dạy giúp soạn ra bài học dựa trên tài liệu được cung cấp. Thử nghiệm này sẽ được thực hiện tại New York trong năm tới.
Skype
Thương hiệu do Microsoft mua lại này cung cấp khả năng dịch thuật theo thời gian thực với 6 ngôn ngữ chính, và sẽ hỗ trợ thêm nhiều ngôn ngữ khác trong thời gian tới.
Khả năng dịch thuật mạnh mẽ của Skype là nhờ trí tuệ nhân tạo.
Hệ thống dịch thuật này có khả năng nhận dạng giọng nói người dùng và chuyển sang chữ viết (text) khi người dùng nói.
Salesforce
Tháng 4/2016, Salesforce mua lại MetaMind, một công ty khởi nghiệp AI chuyên về học sâu. Thương vụ này cho phép Salesforce có thể cung cấp cho khách hàng những giải pháp AI bổ ích thông qua hàng loạt quy trình tự động và cá nhân hóa hỗ trợ khách hàng, tự động hóa marketing và xử lý rất nhiều quy trình kinh doanh khác.
Trước đây, MetaMind từng phát triển một hệ thống độc đáo có khả năng trả lời câu hỏi bằng giọng nói tự nhiên.
Định nghĩa trí tuệ nhân tạo: (AI: Artificial Intelligence) có thể được định nghĩa như một ngành của khoa học máy tính liên quan đến việc tự động hóa các hành vi thông minh. AI là một bộ phận của khoa học máy tính và do đó nó phải được đặt trên những nguyên lý lý thuyết vững chắc, có khả năng ứng dụng được của lĩnh vực này.
Ở thời điểm hiện tại, Thuật ngữ này thường dùng để nói đến các MÁY TÍNH có mục đích không nhất định và ngành khoa học nghiên cứu về các lý thuyết và ứng dụng của trí tuệ nhân tạo. Tức là mỗi loại trí tuệ nhân tạo hiện nay đang dừng lại ở mức độ những máy tính hoặc siêu máy tính dùng để xử lý một loại công việc nào đó như điều khiển một ngôi nhà, nghiên cứu nhận diện hình ảnh, xử lý dữ liệu của bệnh nhân để đưa ra phác đồ điều trị, xử lý dữ liệu để tự học hỏi, khả năng trả lời các câu hỏi về chẩn đoán bệnh, trả lời khách hàng về các sản phẩm của một công ty,…
Nói nôm na cho dễ hiểu: đó là trí tuệ của máy móc được tạo ra bởi con người. Trí tuệ này có thể tư duy, suy nghĩ, học hỏi,… như trí tuệ con người. Xử lý dữ liệu ở mức rộng lớn hơn, quy mô hơn, hệ thống, khoa học và nhanh hơn so với con người.
Rất nhiều hãng công nghệ nổi tiếng có tham vọng tạo ra được những AI (trí tuệ nhân tạo) vì giá trị của chúng là vô cùng lớn, giải quyết được rất nhiều vấn đề của con người mà loài người đang chưa giải quyết được.
Trí tuệ nhân tạo mang lại rất nhiều giá trị cho cuộc sống loài người, nhưng cũng tiềm ẩn những nguy cơ. Rất nhiều chuyên gia lo lắng rằng khi trí tuệ nhân tạo đạt tới 1 ngưỡng tiến hóa nào đó thì đó cũng là thời điểm loài người bị tận diệt. Rất nhiều các bộ phim đã khai thác đề tài này với nhiều góc nhìn, nhưng qua đó đều muốn cảnh báo loài người về mối nguy đặc biệt này.
1 cảnh trong bộ phim “I, Robot” nói về một AI đã tiến hóa, sau đó đã dồn con người vào cảnh “nô lệ” với danh nghĩa bảo vệ con người.
Dự báo cho rằng từ 5 đến 10 năm nữa, ngành khoa học này sẽ phát triển lên tới đỉnh cao. Hãy cùng chờ đợi những thành tựu mới nhất của loài người về lĩnh vực này.
Chúng tôi tin rằng Trí tuệ Nhân tạo sẽ trở thành tiến bộ công nghệ quan trọng nhất và có nhiều lợi ích nhất từ trước đến giờ, giúp loài người giải quyết được những vấn đề lớn mà chúng ta phải đối mặt, từ biến đổi khí hậu tới hệ thống y tế tân tiến. Nhưng để AI có thể thực hiện điều đó, chúng tôi biết rằng công nghệ này phải được xây dựng với một thái độ có trách nhiệm và chúng tôi phải tính đến tất cả những thử thách và nguy cơ tiềm tàng.
Chính vì thế mà những nhà sáng lập của DeepMind khởi xướng Partnership on AI to Benefit People and Society và vì vậy mà chúng tôi có một nhóm chuyên đảm bảo An toàn kỹ thuật AI. Nghiên cứu trong lĩnh vực này cần phải có tính mở và hợp tác để đảm bảo rằng những thực nghiệm tốt nhất được thực hiện một cách rộng rãi nhất có thể, vì vậy mà chúng tôi cũng hợp tác với OpenAI trong nghiên cứu về An toàn Kỹ thuật AI.
Một trong những câu hỏi cốt lõi của lĩnh vực này là làm sao để con người có thể yêu cầu một hệ thống làm điều chúng ta muốn và quan trọng là những gì chúng ta không muốn nó làm. Việc này càng ngày càng quan trọng hơn khi mà những vấn đề chúng ta gặp phải với machine learning đang ngày càng phức tạp và được áp dụng trong thực tiễn.
Kết quả đầu tiên từ sự hợp tác của chúng tôi mô tả một phương pháp để giải quyết vấn đề nêu trên, bằng cách cho những người không có kinh nghiệm về kỹ thuật để dạy cho một hệ thống Reinforcement learning (RL) – một AI học bằng cách thử sai – một mục tiêu rất phức tạp. Như vậy con người sẽ không cần đưa ra một mục tiêu cụ thể ban đầu cho hệ thống. Đây là một bước quan trọng bởi vì hiểu sai mục tiêu một chút thôi cũng có thể dẫn tới những hành vi không mong muốn hay thậm chí nguy hiểm. Trong một số trường hợp, chỉ 30 phút phản hồi từ một người bình thường cũng đủ để huấn luyện hệ thống, bao gồm cả dạy cho nó một hành vi phức tạp hoàn toàn mới, như dạy một robot giả lập cách nhảy blackflips.
Cần tới 900 phản hồi của con người để dạy cho thuật toán cách nhảy backflip
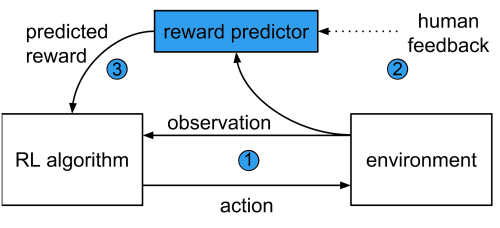
Hệ thống – được miêu tả trong nghiên cứu của chúng tôi Deep Reinforcement Learning from Human Preferences – khác với một hệ thống RL thông thường ở chỗ nó huấn luyện agent (robot hoặc AI) bằng một neural network theo kiểu dự đoán phần thưởng “reward predictor” hơn là kiểu thu thập phần thưởng trong khi agent khám phá một môi trường.
Nó bao gồm ba tiến trình chạy song song:
1.Một Agent Reinforcement learning khám phá và tương tác với môi trường quanh nó, ví dụ như các trò chơi trên máy Atari.
2.Định kỳ, một cặp video clip dài 1 tới 2 giây quay các hoạt động của agent tới một điều hành viên con người và hỏi xem hoạt động trong video nào là cách tốt nhất để đạt được mục tiêu mong muốn.
3.Lựa chọn của con người được dùng để huấn luyện một “reward predictor” , rồi sau đó predictor này sẽ huấn luyện agent. Qua thời gian, agent sẽ học cách để tối đa hóa phần thưởng và cải thiện hành vi của nó theo lựa chọn của con người.
Hệ thống này sẽ tách biệt việc học hiểu mục tiêu và việc học hiểu phương pháp để đạt được mục tiêu đó
Phương pháp học tập lặp lại này đồng nghĩa với việc con người có thể phát hiện và chỉnh sửa bất kỳ hành vi không mong muốn nào, một điểm rất quan trọng của bất kỳ hệ thống an toàn nào. Cơ chế này cũng sẽ không dồn một khối lượng công việc quá lớn lên điều hành viên con người, họ chỉ phải duyệt qua khoảng 0.1% số lượng hành vi của agent để có thể khiến agent thực hiện những gì họ muốn. Tuy vậy, điều hành viên cũng phải duyệt qua vài trăm tới vài nghìn cặp video clip nên thuật toán cần được cải thiện để có thể áp dụng vào các vấn đề thực tiễn.
Điều hành viên sẽ phải chọn một trong hai clip. Trong ví dụ này, đối với trò Qbert, clip bên phải cho thấy hành vi phù hợp hơn để ghi điểm.
Trong trò Enduro, người chơi phải lái một chiếc xe để vượt qua những xe khác. Với trò này thì rất khó để agent có thể học chơi trò này bằng phương pháp thử sai trong thuật toán RL trước đây, phản hồi của con người cuối cùng cũng cho phép hệ thống của chúng tôi đạt được kết quả như con người. Trong những trò chơi khác và các tác vụ robot giả lập, hệ thống của chúng tôi đạt được những kết quả có thể so sánh với hệ thống RL thông thường trong khi một số trò khác như Qbert và Breakout thì nó không thể thực hiện tác vụ.
Nhưng mục tiêu cuối cùng của một hệ thống như này là cho phép con người đặt một mục tiêu cụ thể cho agent kể cả khi nó không xuất hiện trong môi trường. Để kiểm tra việc này, chúng tôi dạy agent nhiều hành vi mới lạ như nhảy backflip, bước đi trên một chân hay học lái xe song song với một xe khác trong Enduro hơn là vượt qua để lấy điểm số cao.
Mục tiêu thông thường của trò Enduro là vượt qua nhiều xe nhất có thể. Tuy nhiên trong hệ thống của chúng tôi, chúng tôi có thể dạy cho agent một mục tiêu hoàn toàn khác, như là lái song song một chiếc xe khác.
Mục tiêu thông thường của trò Enduro là vượt qua nhiều xe nhất có thể. Tuy nhiên trong hệ thống của chúng tôi, chúng tôi có thể dạy cho agent một mục tiêu hoàn toàn khác, như là lái song song một chiếc xe khác.
Mặc dù những bài kiểm tra đó cho thấy một vài kết quả khả quan, một số khác cho thấy những hạn chế của hệ thống. Cụ thể hơn, cài đặt của chúng tôi dễ bị reward hacking hay đánh lừa hàm tính thưởng – nếu phản hồi của con người bị ngắt quãng trong giai đoạn đầu của huấn luyện. Trong trường hợp đó, agent sẽ tiếp tục khám phá môi trường game trong khi reward predictor bị buộc phải ước lượng phần thưởng cho các tình huống mà nó không nhận được phản hồi nào. Việc này có thể dẫn tới đánh giá quá cao phần thưởng, khiến agent học những hành vi sai, thường là kỳ lạ. Một ví dụ có thể thấy ở video tiếp theo, khi mà agent nhận thấy đập bóng qua lại là một chiến thuận tốt hơn là thắng hay mất điểm.
Agent đã qua mặt hàm tính thưởng của chính nó, và quyết định chỉ đánh bóng qua lại thay vì cố gắng ghi điểm hay để mất điểm.
Agent đã qua mặt hàm tính thưởng của chính nó, và quyết định chỉ đánh bóng qua lại thay vì cố gắng ghi điểm hay để mất điểm.
Hiểu được những thiếu sót như vậy là tối quan trọng để đảm bảo chúng tôi tránh được những thất bại và phát triển được một hệ thống AI có hành vi như mong muốn.
Còn rất nhiều công việc phải làm để kiểm tra và nâng cấp hệ thống này, nhưng nó đã cho thấy một số bước đột phá đầu tiên trong việc xây dựng một hệ thống có thể được dạy bởi những người dùng không chuyên nghiệp, mang tính kinh tế với số lượng phản hồi mà nó cần và có thể mở rộng ra nhiều vấn đề khác.
Các lĩnh vực cần khám phá khác có thể bao gồm việc giảm thiểu số lượng phản hồi của con người hay cho phép con người phản hồi qua giao diện ngôn ngữ tự nhiên. Việc đó sẽ đánh dấu một bước thay đổi trong việc tao ra một hệ thống có thể dễ dàng học từ những hành vi phức tạp của con người và là một bước quan trọng hướng tới việc tạo ra AI có thể làm việc với và vì loài người.
Lưu ý: Bài viết này được các nhà khoa học của DeepMind viết dựa trên nghiên cứu chung với OpenAI. Các nhà khoa học của OpenAI cũng đã viết một bài blog khác dưới góc nhìn của họ. Chúng tôi sẽ giới thiệu tới độc giả bài viết đó trong tương lai gần.
Theo Shane Legg, Jan Leike, Miljan Martic (DeepMind)