
Đây sẽ là một dự án làm cho vui. Mình sẽ crawl toàn bộ các bài thơ của trang: http://vanhoc.xitrum.net/thoca/ về đặt lên wordpress xem chơi.
Bắt đầu từ ngày mai nhé 2019-10-11. 😀
Update: 11/10/2019
Đã triển khai việc crawl danh sách các link liên quan đến thơ ca nội bộ của trang. Kết quả code và dữ liệu nằm tại đường dẫn:
- Code: https://github.com/phamkhactuy/python_crawl_thoca/blob/master/20191011_crawl_link.py
- Data: https://github.com/phamkhactuy/python_crawl_thoca/blob/master/thoca.csv
Với dữ liệu này bước tiếp theo phải xử lý:
- Cần làm sạch dữ liệu, chỉ lấy link có dữ liệu là bài thơ mà thôi
- Tiếp tục crawl dữ liệu nội bộ trang, loại bỏ trùng lặp
- Dựng local wordpress để đẩy dữ liệu vào
Update: 08/11/2019
Lơ là một thời gian mới quay lại triển nốt cái này cho dứt điểm.
Dựng local wordpress để đẩy dữ liệu vào: phần này đơn giản sử dụng phần mêm Xampp, sau đó tải wordpress về cài đặt là xong.
Đầu tiên bóc tách thử dữ liệu của một link
Đầu tiên bóc tách thử dữ liệu của một link thì phát hiện thấy cấu trúc của xitrum viết theo dạng cũ sử dụng bảng. Tạm thời chỉ cần lấy Tiêu đề và nội dung của bài viết. Tiêu đề thì ta chỉ lấy riêng text còn nội dung thì lấy cả cấu trúc HTML (gồm div, thẻ b…). Phần này sử dụng Python với thư viện BeautifulSoup, đáng lưu ý là việc lấy thẻ table với các tham số đặc biệt của table chứa nội dung bài thơ là: {“border”:”0″, “width”:”90%”,”cellpadding”:”3″,”cellspacing”:”0″}
Chi tiết code tại: https://github.com/phamkhactuy/python_crawl_thoca/blob/master/Get_content_from_link.py
Tiếp đến ta sẽ tiến hành đưa dữ liệu vào bảng của wordpress là một bài viết mới. Mỗi một bài viết mới là một dòng dữ liệu trong bảng POSTS. Ta sẽ tiến hành chuẩn bị dữ liệu để insert vào bảng này. Ta cần lưu ý một số điểm:
- Để kết nối với CSDL và hiển thị tốt Tiếng Việt ta sử dụng mã utf-8 (# –– coding: utf-8 –-) trong file python.
- ID của bảng POSTS sẽ tăng dần nên phải vào đó lấy ID mới nhất và cộng thêm 1. Với ID này ta cũng dùng để làm đường dẫn đến bài viết luôn.
- User thì ta sử dụng user mặc định Admin có ID là 1.
- Thời gian tạo và sửa đổi ta sử dụng hàm NOW() hoặc SYSDATE()
Chi tiết code tại: https://github.com/phamkhactuy/python_crawl_thoca/blob/master/Save_content_in_wordpress.py
Load dữ liệu từ file csv lên với thư viện Pandas. Đối với file csv ta cần chuẩn hóa bỏ toàn bộ dấu ngoặc kép và loại bỏ các link trùng bằng excel. Mục tiêu của ta sẽ lấy dữ liệu của từng link và đưa vào bảng POSTS của wordpress. Thử load và in ra màn hình lần lượt từng row trong file csv.
Chi tiết code tại: https://github.com/phamkhactuy/python_crawl_thoca/blob/master/Get_link_from_filecsv.py
Cuối cùng ta có thể ghép code
Cuối cùng ta có thể ghép code các phần trên này lại để lấy lần lượt nội dung từng link để đưa vào CSDL wordpress. Trong phần này ta cần lưu ý đối với mỗi link, ta lấy được 2 cấu trúc table như nhau về định danh (cùng là table và có tham số table là {“border”:”0″, “width”:”90%”,”cellpadding”:”3″,”cellspacing”:”0″}) nhưng 1 cái sẽ là nội dung ta cần lấy. Một cái sẽ là gợi ý các link khác mà ta không cần vì nó không phải là nội dung thơ văn. Và một điều lưu ý nữa là chỉ các link có nội dung là bài thơ mới có cấu trúc ta đã chỉ ra ở trên, các link list tác giả, list bài thơ, list mục sẽ không cấu trúc đó nên sẽ không insert vào hệ thống (Nếu cùng cấu trúc thì ta phải chuẩn hóa các link trước).
Chi tiết code tại: https://github.com/phamkhactuy/python_crawl_thoca/blob/master/Finall_code_crawl.py
Ta đã có kết quả cho việc crawl này

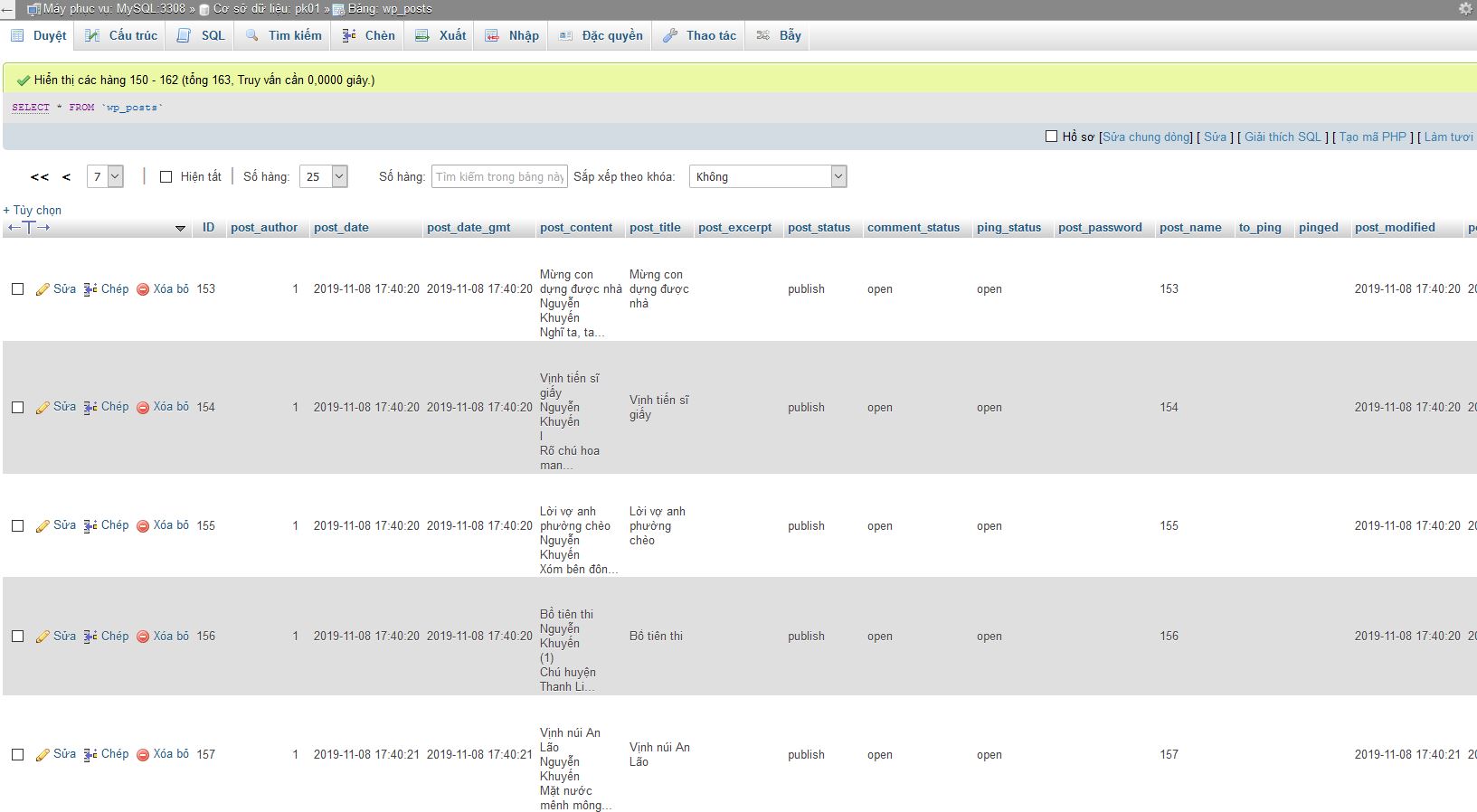
https://raw.githubusercontent.com/phamkhactuy/python_crawl_thoca/master/Trang_quan_tri.JPG
https://raw.githubusercontent.com/phamkhactuy/python_crawl_thoca/master/insert_POSTS.JPG
https://raw.githubusercontent.com/phamkhactuy/python_crawl_thoca/master/Giao_dien_trang.JPG